WhiteURLScan 网站信息扫描工具
项目简介
WhiteURLScan 是一款功能强大且高效的网站 URL 扫描与信息采集工具,旨在帮助用户快速、安全地扫描和采集网站信息。它支持多线程并发扫描、递归爬取、自动拼接、敏感信息检测、外部 URL 收集等多种功能,广泛应用于安全测试、信息收集、资产梳理等领域。
主要功能
- 递归扫描:自动扫描网站所有可达 URL,并去除重复项。
- 智能路径拼接:识别并拼接各种相对/绝对路径,包括自定义基地址、API 路由、路径路由拼接(fuzz 模式)。
- 敏感信息检测:检测页面中的敏感信息,如身份证号、手机号、API 密钥等。
- URL 收集:自动收集 URL,并统计访问结果。
- 高效扫描:多线程并发扫描,速度快,支持批量 URL 扫描。
- 实时输出:实时彩色输出,结果自动保存为 CSV 文件。
- 自定义设置:支持自定义请求头、代理、黑名单域名、扩展名过滤等。
- 调试日志:提供丰富的调试与日志输出,方便问题排查和优化。
安装依赖
建议使用 Python 3.7 及以上版本。
pip install -r requirements.txt主要依赖包:
- requests
- beautifulsoup4
- tldextract
- colorama
如缺少依赖,可手动安装:
pip install requests beautifulsoup4 tldextract colorama运行参数
-u起始URL-f批量URL文件-delay延迟时间(秒)-workers最大线程数(如 30)-timeout请求超时(秒)-depth最大递归深度-out实时输出文件路径-proxy代理(如 http://127.0.0.1:8080)-debug调试模式(1开启,0关闭)-scopeURL扫描范围模式 0主域 1外部一次 2全放开 3白名单模式-danger危险接口过滤(1开启,0关闭)-fuzz自定义 URL 拼接
配置说明
首次运行会自动生成 config.json,可根据实际需求修改:
start_url:起始扫描 URLmax_workers:最大线程数timeout:请求超时时间(秒)max_depth:最大递归深度(深度过大爬取所有链接后将直接结束程序)output_file:实时输出结果文件blacklist_domains:黑名单域名extension_blacklist:过滤的文件扩展名max_urls:最大扫描 URL 数量smart_concatenation:智能 URL 拼接debug_mode:调试模式(0 关闭,1 开启)scope:URL 扫描范围模式 0 主域、 1 外部链接只访问一次 、2 无限制 、3 白名单模式(只访问白名单域名)whitelist_domains:白名单域名(scope=3 时使用)danger_api_list:危险 API 过滤列表is_duplicate:是否输出重复链接(返回内容相同即视为重复,0 关闭 1 开启)custom_base_url:自定义基地址列表(fuzz 模式下生效)path_route:自定义路径路由列表(fuzz 模式下生效)api_route:自定义 API 路由列表(fuzz 模式下生效)fuzz:是否启用自定义 URL 拼接参数(0 关闭,1 启用)- 其他参数详见 config.json
使用方法
1. 单个 URL 扫描
python WhiteURLScan.py -u https://example.com -workers 20 -delay 1 -timeout 8 -depth 3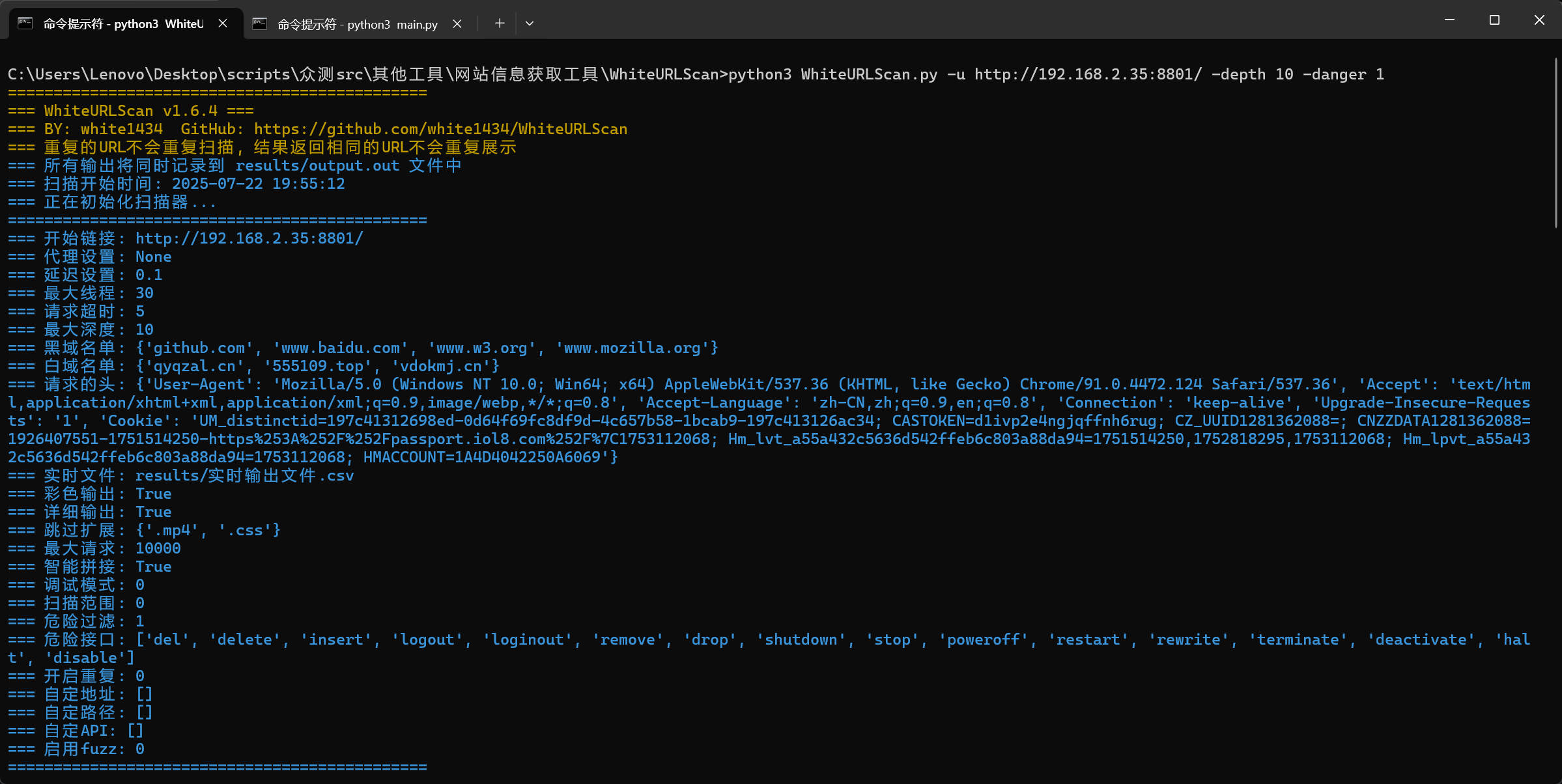
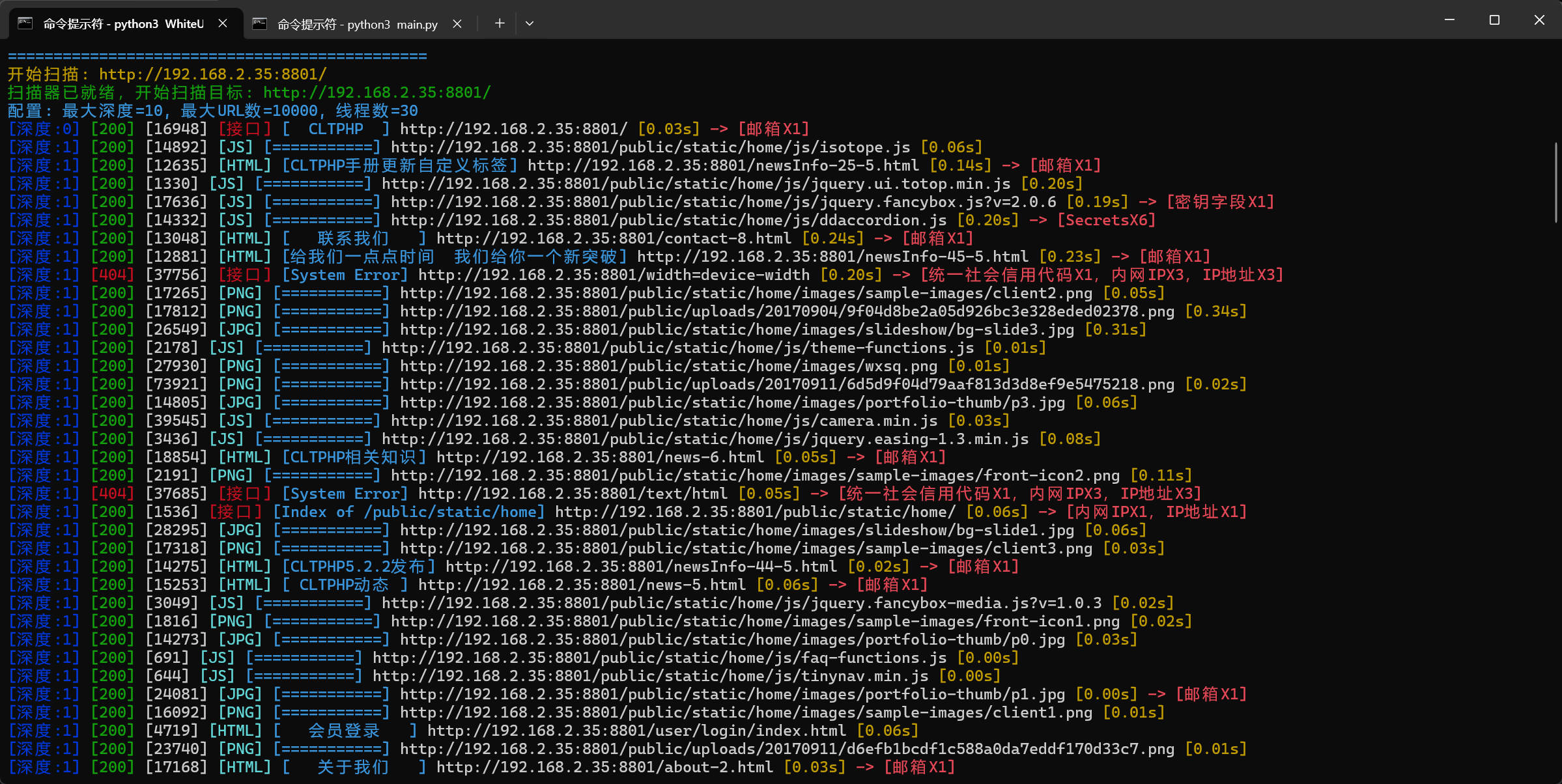
2. 批量 URL 扫描
将多个 URL 写入 url.txt,每行一个,然后:
python WhiteURLScan.py -f url.txt -workers 20 -delay 1 -timeout 8 -depth 33. 启用自定义 URL 拼接(fuzz 模式)
python WhiteURLScan.py -f url.txt -fuzz 1 -proxy http://127.0.0.1:8080需要在配置文件中配置自定义参数custom_base_url、path_route、api_route 如下会自动拼接,https://example.com/#/扫描到的路径 , https://example.com/melody/api/v1/扫描到的路径
"custom_base_url": ["https://example.com/"],
"path_route": ["/#/"],
"api_route": ["/melody/api/v1"],4. 自定义扫描范围(scope 模式)
python WhiteURLScan.py -f url.txt -fuzz 1 -scope 3 -danger 1 -proxy http://127.0.0.1:8080URL 扫描范围模式 0 主域、 1 外部链接只访问一次 、2 无限制 、3 白名单模式(只访问白名单域名)
如目标为: https://example.com/:
-scope 0: 只扫描example.com域名(或ip),会记录外链到文件中-scope 1: 扫描example.com域名(或ip)之外的不重复链接一次(不在外域递归)-scope 2: 扫描所有链接,停止只看-depth深度(会在外站递归)和max_urls限制-scope 3: 扫描白名单域名(需配置白名单参数),只扫描whitelist_domains白名单内域名
输出说明
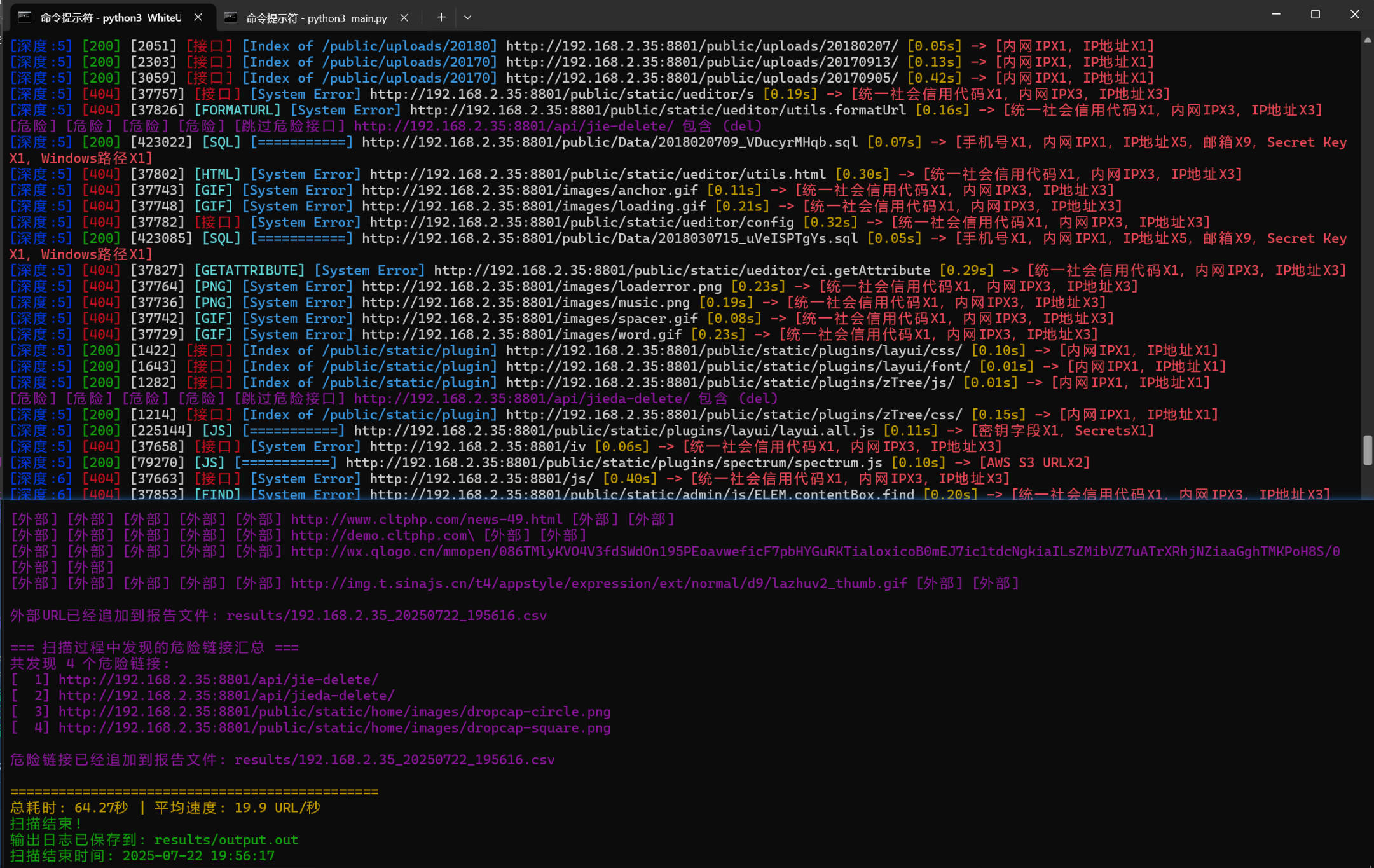
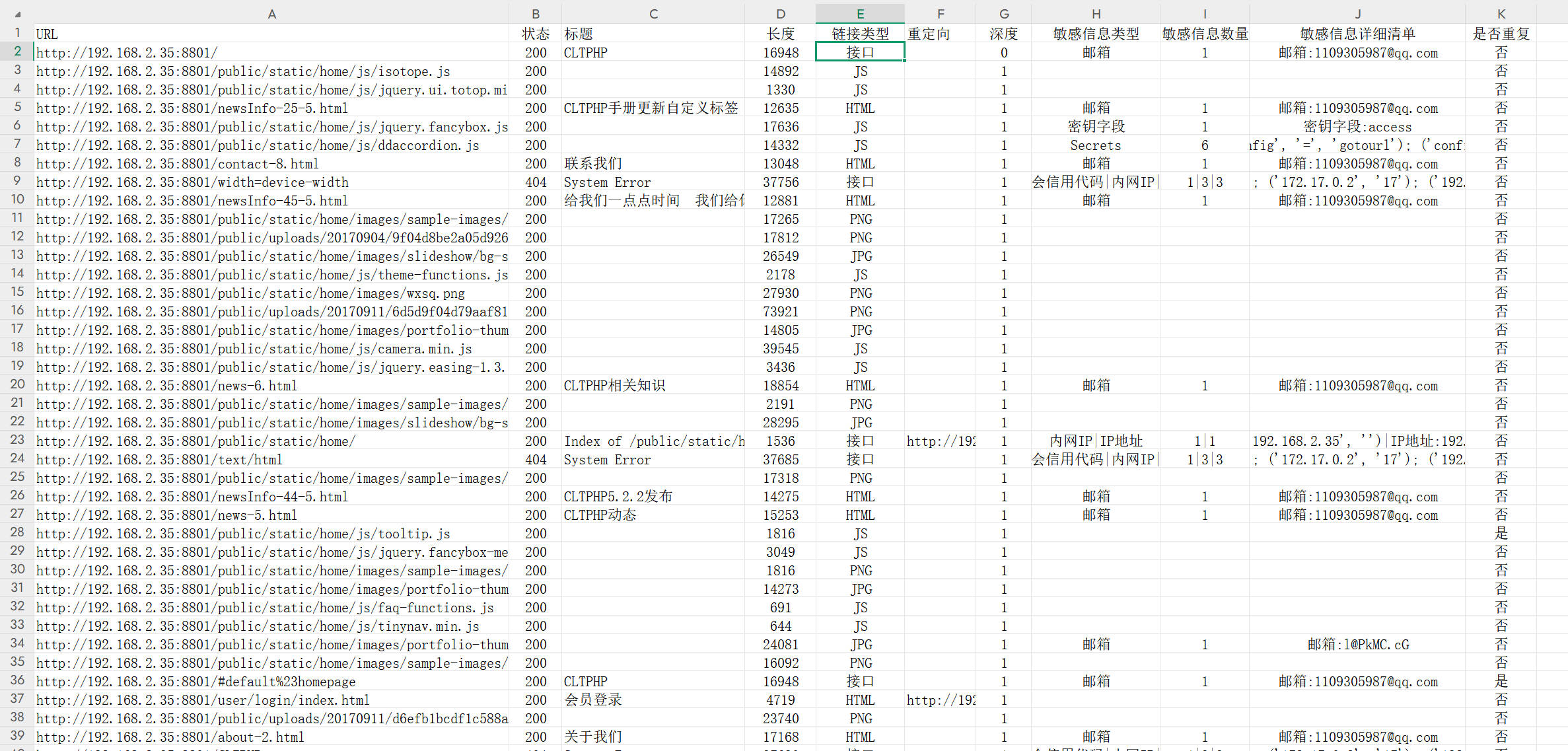
- 实时扫描结果会输出到控制台,并保存到
results/目录下的 CSV 文件 - 外部 URL 访问结果也会自动追加到报告文件
- 日志文件为
results/output.out
常见问题与建议
- 建议合理设置线程数、递归深度、延迟时间,避免对目标站点造成压力
- 递归深度过大时,程序会扫描所有页面链接后自动结束,注意最大 URL 数量限制
- 敏感信息检测基于正则表达式,结果仅供参考,欢迎补充
- fuzz 模式(需配置自定义参数)适合接口批量爆破、路径探测等高级用法,普通扫描建议关闭
- 请勿将本工具用于非法用途
TODO
- [X] 多线程功能
- [X] 代理功能
- [X] 正则匹配功能
- [X] 文件保存功能
- [X] 参数配置功能
- [X] 敏感信息检测功能
- [X] 危险接口过滤功能
- [X] 域名黑名单检测功能
- [X] 域名白名单模式
- [X] 自定义请求头功能
- [X] 自定义 base url 进行拼接(需启用 fuzz 模式)
- [X] 自定义 fuzz 列表(需启用 fuzz 模式)
- [X] 自定义 api 路径(需启用 fuzz 模式)
- [X] webpack 打包网站 js 提取(暂时只匹配 chunk.a2d74a98.1ea71fd1.js 格式,且固定为 /static/js/chunk.a2d74a98.1ea71fd1.js 路径 )
- [X] 多链接扫描结果汇总
- [ ] 指纹识别功能
- [ ] POST 请求检测
- [ ] 动态 api 加载
- [ ] 浏览器模拟访问
- [ ] 网页返回类型细分
- [ ] 优化敏感信息匹配
- [ ] 优化路径匹配 (HAE规则误报太多,等待优化)
- [ ] 优化拼接方式
- [ ] 优化代码结构